ML Basics: Markov Models Write Fairy Tales
In my talk on Natural Language Processing I talk about chatbots a bit. One way to build things like Twitter bots is to use Markov Chains. If you read the formal papers on Markov Chains and Markov Models, they seem quite complex, but they are pretty simple. The basic rule that all Markov processes must satisfy is that what happens next must be determinable only from the current state. In a chatbot, this means that I must be able to generate the next word based only on the current word. In the sentence “The cat runs after the ___” I can only use the last “the” to figure out what I should put in the blank. Predictive text on cell phone keyboards is another place where Markov models are commonly used.
Problem and Dataset
I am going to demonstrate Markov Models by building a text generator. To do that I need a corpus of text to base my generator on. I am using Grimm’s Fairy Tales from Project Gutenberg. This dataset has the advantage of being easily available, small but still interesting, and stylistically consistent. By stylistically consistent I mean each fairy tale follows a similar form with roughly the same complexity in vocabulary and grammar. Fairy stories are also pretty well known. That makes it is easy to get a “gut feel” for how well the generator worked. I do not base important decisions on “gut feel, “ but I feel it is okay for evaluating toy code.
State Machines and Graphs
I find it easiest to think of Markov Models as state machines. There is some list of possible states (words, observations, status codes) and a set of rules for transitioning between them based only on the current state.
You may remember “numbering off” for games in school. Each person says a number 1 - n to form n teams of approximately equal size. A state machine for making three teams could have the most recently said number as the state. State 1 could go to state 2, state 2 to state 3, state three back to state 1, and all the states could go to a finished state if there were no more people.
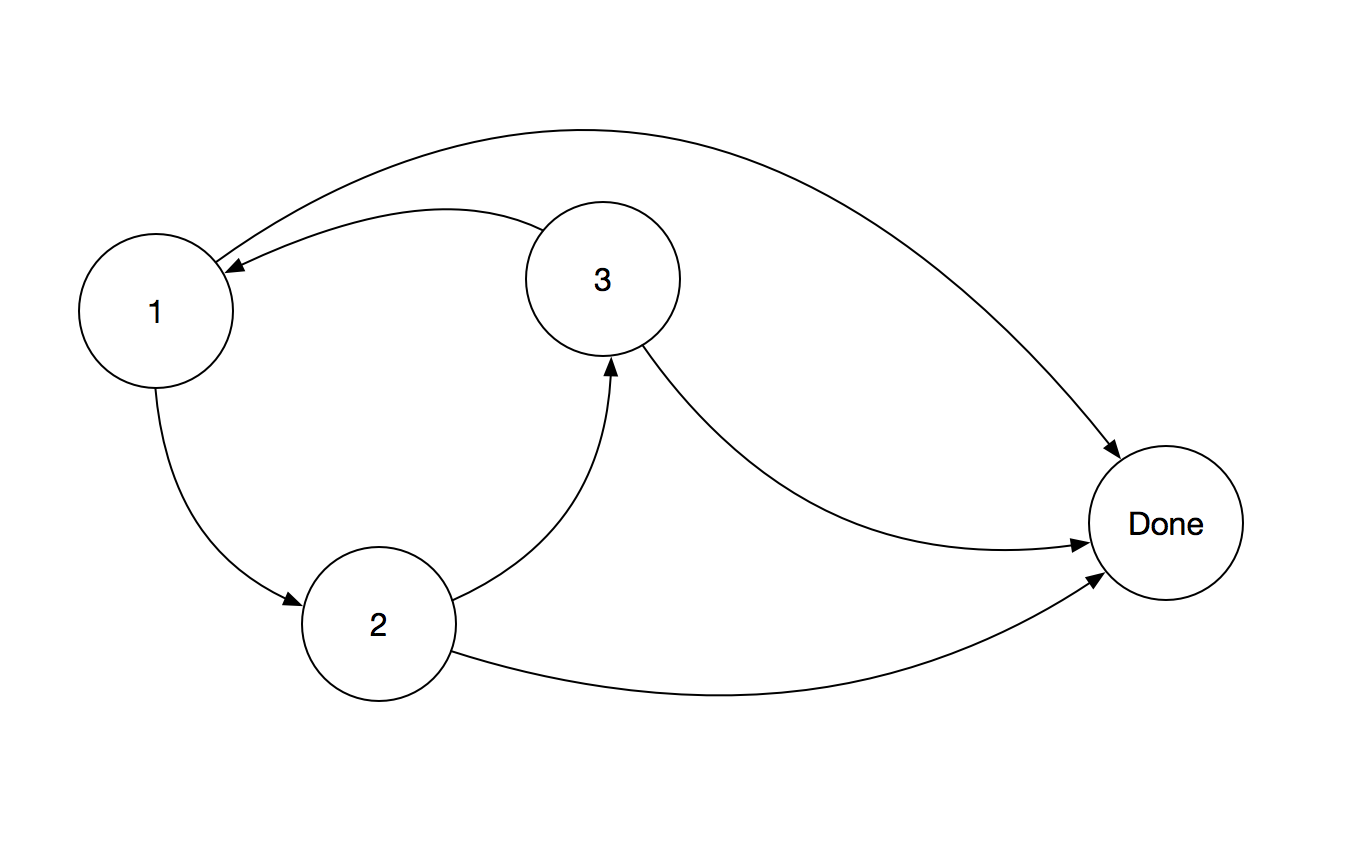
This visualization is an example of a directed graph. Each circle represents a state. In a graph, those are called nodes. The connections between the nodes are called edges. The edges represent state transitions in our state machine.
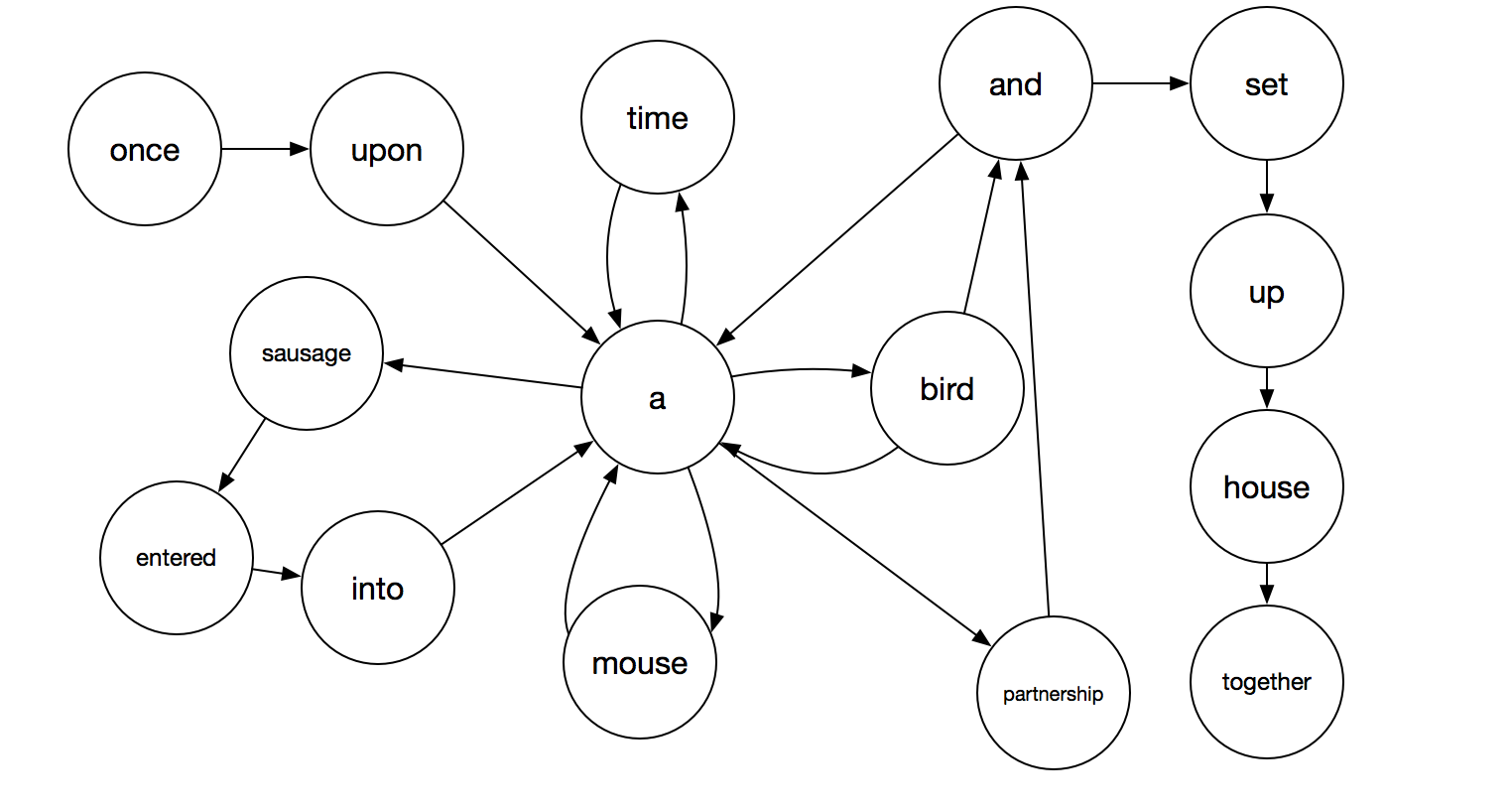
In the fairy tale generator, the states are words or punctuation. Each state is connected to other states/words if those words appear together in the text. Here is the first sentence of The Mouse, The Bird, and The Sausage:
Once upon a time, a mouse, a bird, and a sausage, entered into partnership and set up house together.
The state machine for this sentence (without punctuation) is below. You can see that it is much more complex than the numbering off state machine above. Common words like “a” and “and” are connected to multiple other states.
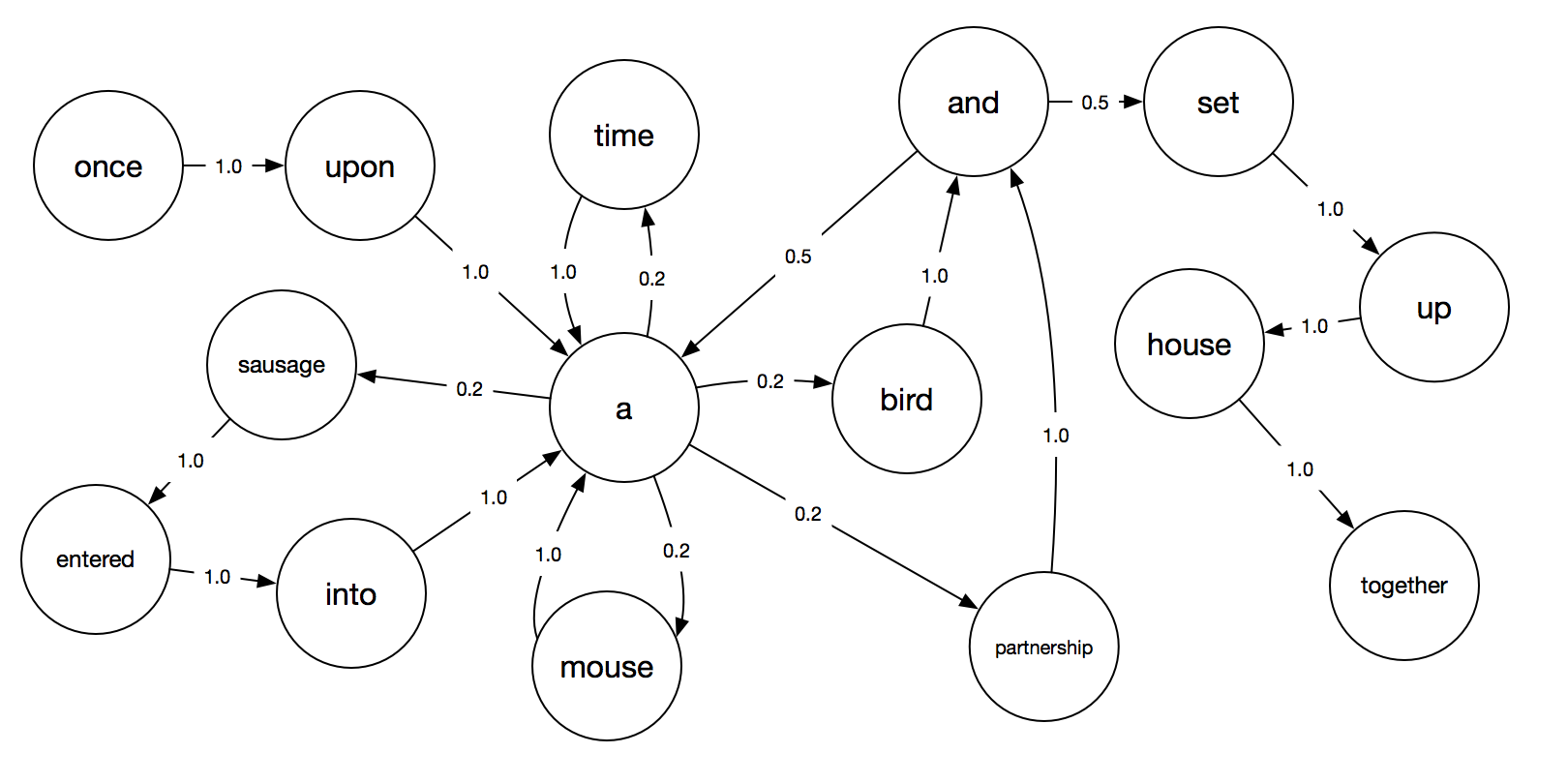
This is most of what we need for the Markov Model. The last bit is including probabilities. A word like “once” is more likely to be followed by words like “upon” and “more” than it is to be followed by a word like “blue.” We can reflect this in our model by setting the probability that each connected state will be next. Here’s the same state diagram as above, but with probabilities added to each edge.
The Code
There are several ways to implement a Markov Model. I am using Ruby’s Array#sample method which selects randomly from an array and using a Hash of Arrays as my primary data structure.
The first step in creating the model is importing the text. I am doing a long sequence of transformations on the text to get it ready for the next step. First I split the file by word boundaries. I tried splitting it on whitespace and words but doing that lost the punctuation. Then I strip out all the whitespace and downcase the word using map { |x| x.sub(/\s+/, "").downcase }. Finally, I remove any elements that are empty.
words = File.read("Fairy Tales.txt").split(/(\b)/).map{ |x| x.sub(/\s+/,"").downcase}.reject(&:empty?)Now I need to make my state machine using the hash of arrays. I know it seems weird to represent a state machine this way, but it works. The hash keys will be words, and the values will be an array of words. If my current word is “throwing” I look that up in the hash and find ["down", "himself", "one", "out"] as the value. To select the next state I use Array#sample to select one of those words at random. That word, let’s say “out”, becomes the next state.
To fill the hash I use Array#each_cons(2), which returns pairs of words from my words array. This approach adds words to the array every time they appear. For example, in the Grimm’s fairy tale text the word “till” appears after the word “waited” six times but the word “here” only appears once after “waited”. “till” will be inserted into the array all six times and thus will be six times as likely to be selected. This ensures that the next word is selected according to the probabilities of that word pair in the original text.
frequencies = Hash.new { |h, k| h[k] = [] }
words.each_cons(2) do |w1, w2|
frequencies[w1] << w2
endNow I can generate the text. I start by taking a random word from the words array. Then I look up that word in the frequencies hash and select a random word from the associated array and add that to my generated fairy tale. Once I have a series of words I join all the words together separated by spaces and print out the resulting “fairy tale.”
generated = [words.sample]
100.times do
next_word = frequencies[generated.last].sample
generated << next_word
end
puts generated.join(" ")Here is one example of a fairy tale my code generated.
trying to the boy , but the courtyard , he was as beautiful that could find i will marry you or good for three - plank , but they could to try him , but when he ought to eat some more than two eldest still deeper and feet , and there because ,’ she missed the little son ;‘ what bird a hare , and you have been given her bed . then flew down , and chilly , they could do all gone out to speak , she again ordered him till the branches ; but over stock of
Improvements and Extensions
This version of a Markov text generator is very simple. Although performance is satisfactory on small datasets, on large enough datasets the memory needed for the hash of arrays could be problematic. In that case, you can use a count of how many times each word appears after the associated key. I implemented this as well, and the code is here. It is over twice as long, so I chose to walk through the simpler version in this blog post.
I would also like to handle punctuation better. The generated code puts spaces around punctuation which looks unnatural. It also doesn’t handle paragraph breaks, and combinations of punctuation very well. I didn’t bother stripping titles out of the text I used and I probably should have. I may even want to do a separate text generator for fairy tale titles.
There are libraries that implement Markov models in many languages. If I were serious about generating text or modeling another problem with Markov models I would use one of the libraries rather than write my own. However, there is value in understanding what is going on under the hood. I was surprised at how simple it was to implement a Markov model. The papers on this topic are full of equations, and Greek letters but the underlying concepts are very accessible.
I want to give special thanks Alpha, Erik, and Ryan for helping me find the simplest way to implement this. If you have other Machine Learning concepts that you would like me to explain let me know in the comments or on Twitter.
The code for this post is located here.