Vertex AI Agent Builder Demo from I/O
At Google I/O this year, I did a demo of Vertex AI Agent Builder, where I built a simple agent that could help you reserve a picnic shelter at a local park with some prompt engineering but no traditional code. I’d never used Agent Builder before I started working on that demo. Building the demo taught me about the product’s strengths and weaknesses and how to use it effectively. I’m sharing what I’ve learned.
Lesson #1: Every Field Matters
In the Agent Builder experience, you see text fields like name, description, and company name. When I was first experimenting with Agent Builder, I did what I always do when testing software and put nonsense data into these fields—things like “test123” or “my description.” While the tool accepts this, I was struggling with inconsistent responses from the agents I created.
Reading through the docs to debug the issues I was seeing, I realized that all those text fields are used by the LLM in the prompts that it constructs. The company name helps the LLM understand the context it is in. The name and description of tools and specific agents help agents understand how to use tools or interact with other agents. Those fields are just as important as the ones that look more technical or “codey.”
Once I started putting accurate and detailed information in those fields, my agent performed much more consistently. I learned my lesson: the agent uses every bit of information, so take every field seriously. Put clear, accurate, and descriptive text into each and every field. Every field is used.
Lesson #2: Using APIs is easy
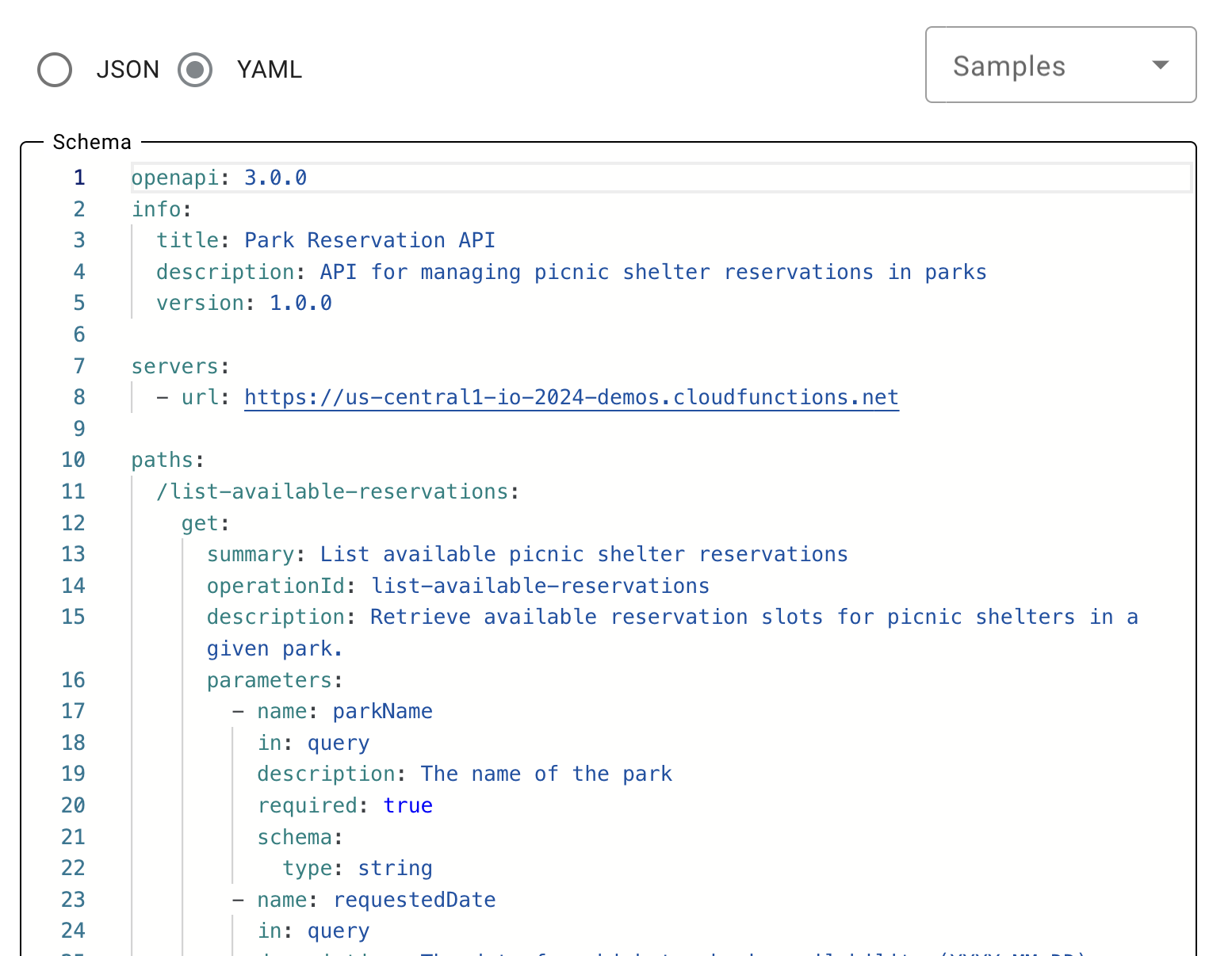
I was shocked at how easy Vertex AI Agent Builder made it to integrate my agent with an API. It was three simple steps: write the description, paste in OpenAPI spec for the API, and then set up auth. As someone who’s spent the last 20+ years coding, it feels slightly uncomfortable that I don’t have to tell the agent how to access the API or write the prompt myself. But you don’t.
For this demo, I stubbed out an API to get available reservations and make reservations and hosted the two endpoints on Cloud Functions. The code is available on GitHub. The API has two endpoints and returns hardcoded answers.
I used what I learned in lesson 1 and made sure the tool’s name was simple and descriptive, the description clear, and the verbs used were the same as those of the actual API endpoints.
Lists the available reservation times for picnic shelters at specific parks, on specific days. Allows users to make a reservation for a shelter at a specific park, day, and time.”
I generated the OpenAPI YAML using Gemini. The prompt was very similar to the description above but with the actual endpoints and URLs called out. It needed a few small tweaks to the description and how the URLs were specified, but using Gemini saved me a bunch of time. Once it was done, I copied and pasted it into the Agent Builder UI.
Lastly, I had to ensure the agent could access my API. Since everything was hosted in the same project, I just had to grant the Vertex Agent service account function invocation privileges for the two functions from the Cloud Functions permissions tab..
Overall, setting up the API tool took me about an hour. Most of that was making minor tweaks to the OpenAPI YAML and figuring out where to grant function invoker permissions in the Google Cloud UI. It really does “just work” and is much simpler than I imagined.
Lesson #3: Using data stores is harder
The original version of the demo had an additional component that allowed me to ask the agent free-form questions about the parks. Like “which parks have wading pools or splash pads.” To answer these questions, the agent was instructed to use a data store tool. The data store tool, in turn, was set up to look at a Cloud Storage bucket that contained a download of all the information on parks I could find in the City of Seattle’s Open Data Portal.
I ended up cutting this from the demo, partly for time but also because I couldn’t make it work consistently. Building a data-based agent that can answer arbitrary questions is harder than I thought it would be.
The first thing I had to tackle was creating the data store itself. The UI makes it pretty straightforward but you do need to ensure that your data store, agent, and app are all in compatible regions. I lost an hour or two debugging issues that turned out to be having things in the wrong places.
The second issue I ran into was that my data wasn’t in the correct format for the tool. The open data portal provided the data in structured formats: CSV or XML. The data store tool currently supports web pages, Q&A formatted structured data, or unstructured data. My CSVs weren’t web pages or Q&A formatted, so I had the tool treat them as unstructured data. It turns out that treating structured data as unstructured data doesn’t work well, especially when using a model primarily trained on natural language, not machine-readable formats like CSV. There are many ways to address this mismatch including reformatting the data, creating custom agents, or building this app as a RAG solution myself. I haven’t tried all these yet, if I do they’ll become part 2 of this blog.
While I could setup the agent to use the data store, the responses were inconsistent. On one run it would correctly tell me which parks had splash pads or wading pools. On a subsequent run it might give an incorrect answer. And on another run it would say “unable to process request” or similar. It was also unable to reliably answer questions that
On one run the tool would correctly respond that South Lake Union park has a splash pad. The next time I tried it, it would incorrectly tell me that Harrison Ridge Greenbelt had a wading pool. On a third try it would tell me it was unable to process the request. There didn’t seem to be any rhyme or reason to it .
This is almost certainly because the data I gave it wasn’t what it was designed for. That was my mistake, but it was also disappointing since my programmer brain I assumed that clean, structured data would actually be easier to work with than raw natural language text.
Overall Lesson Learned
I really liked learning Agent Builder and look forward to trying the new features they add. But the most important thing I learned through this process is that what I, as a programmer, think is easy is not necessarily what is easy for an LLM. I knew this intellectually, but it had been a while since I had experienced it firsthand.